

최근에 고객 세분화(Customer Segmentation) RFM 모델 디버깅 작업과 팀원 중 한분께서 Session Based RS를 고안하실 때 필요한 순차 데이터(Sequential Data) 전처리 작업을 스파크로 진행하면서 경험하였던 것들 중 몇 가지를 공유하고자 합니다.
Spark Tuning
몇 가지 전제들
‘Data Skewness in spark’를 전개 하기 위해서 필요한 몇 가지 점들을 공유하겠습니다.
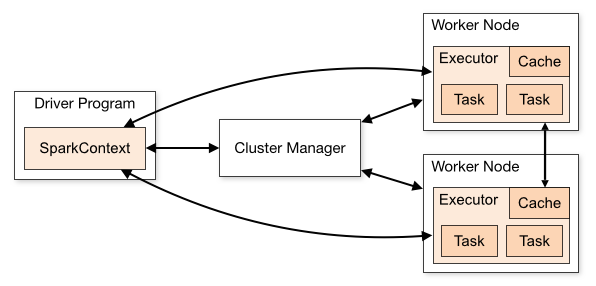
스파크는 기본적으로 다음 이미지와 같이 동작합니다. Local Mode도 지원하지만 실무에서는 Cluster Mode를 일반적으로 활용합니다. 스파크 애플리케이션의 개수가 RFM 뿐만 아니라 다른 어플리케이션도 존재하므로 클러스터 매니저는 YARN으로 설정하고 처리해야 하는 데이터의 기간이 길고 크므로 Driver Memory와 Executor Memory는 충분히 지정하였습니다.
다음으로 스파크가 제공하는 Join에 대해 살펴보겠습니다. 스파크는 아래의 표와 같이 다양한 조인 표현식(Join Expression)을 제공합니다.
| 공통의 키 | ROW 처리 방법 | |
|---|---|---|
| Inner Join | O | Left dataset key and Right dataset key |
| Outer Join | O | Left dataset key or Right dataset key |
| Left Outer Join | O | Left dataset Key only |
| Right Outer Join | O | Right dataset key only |
| Left Semi Join | O | Left data set key matching Right dataset key |
| Left Anti Join | O | Left data set key not maching Right dataset key |
| Natural Join | X | Implicit join |
| Cross Join | X | Catesian Join |
조인할 때 스파크는 셔플 조인(Shuffle Join)과 브로드캐스트 조인(Broadcast Join)방식 중 하나의 통신 방식을 사용합니다.
- Shuffle Join
- Shuffle Join은 전체의 노드간의 통신을 발생 시킵니다.
- 개별 데이터프레임의 파티션에서 Data Skewness가 발생할 경우 Shuffle Join의 Cost는 기하급수적으로 늘어날 것입니다.
- 일반적으로 Join의 대상이 되는 테이블이 클 경우 Shuffle Join이 활용됩니다.
- Broadcast Join
- Shuffle Join과 다르게 Broadcast Join은 Join의 대상이 되는 테이블의 크기 차이가 클 경우 적용됩니다.
- 만약 Low Level이 아닌 High Level API를 활용하면 Optimizer에서 Broadcast join을 사용하도록 힌트를 줄 수 있지만 일반적으로 스파크 자체내에서 자동으로 Broadcast 방식으로 통신하는 것을 쉽게 알 수 있습니다.
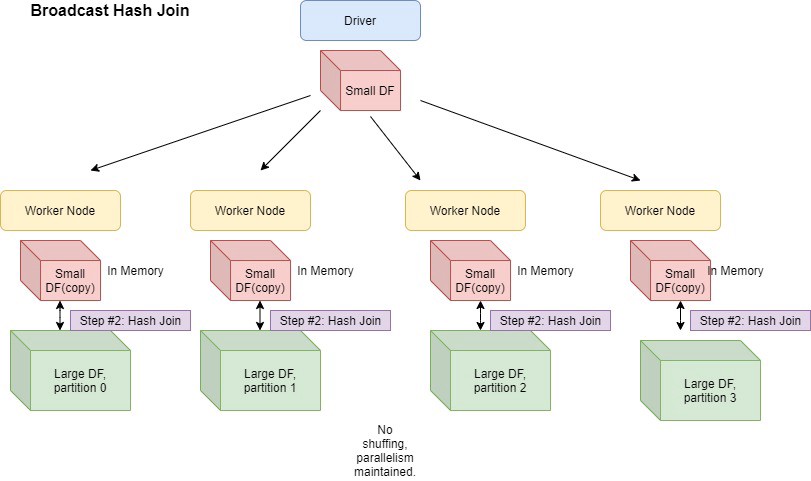
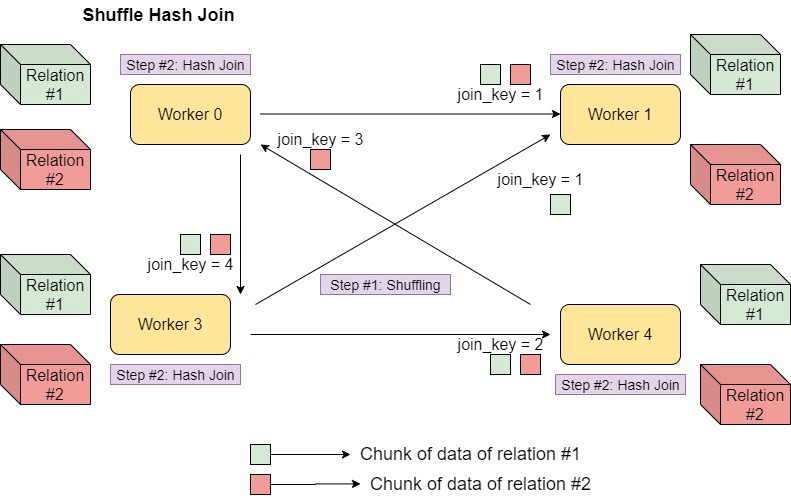
특히 Cross Join을 시행할 때는 두 가지 경우의 수가 있을 것입니다.
- Small DataFrame Cross Join
- 만약 Join의 대상이 크지 않을 경우 데이터프레임의 파티션은 다음과 같을 것입니다.
- \(\ N(Partitions) \,of \,left \,DF = \,N(Partitions) \,of \,right \,DF = N(Partitions) \,after \,crossJoin \,DF\)
- Large DataFrame Cross Join
- 반면 Join의 대상의 크기가 클 경우 데이터프레임의 파티션은 다음과 같을 것입니다.
- \(\ N(Partitions) \, after \, crossJoin DF = N(Partitions) \, of \, left \, DF * N(Partitions) \, of \, right \, DF\)
Data preprocessing in RFM
간단한 배경 설명을 하고 스파크 튜닝 부분을 전개하겠습니다. RFM 모델은 이커머스상에서 활동한 고객 행동 데이터 중 R(Recency), F(Frequency), M(Monetary value)를 인자로 사용하여 고객을 세분화합니다. 최종적인 결과는 아래의 이미지와 유사하지만 Monetary value가 추가적으로 포함된다는 점과 내부적인 고객 세분화와 연관된 연산 과정이 다릅니다.
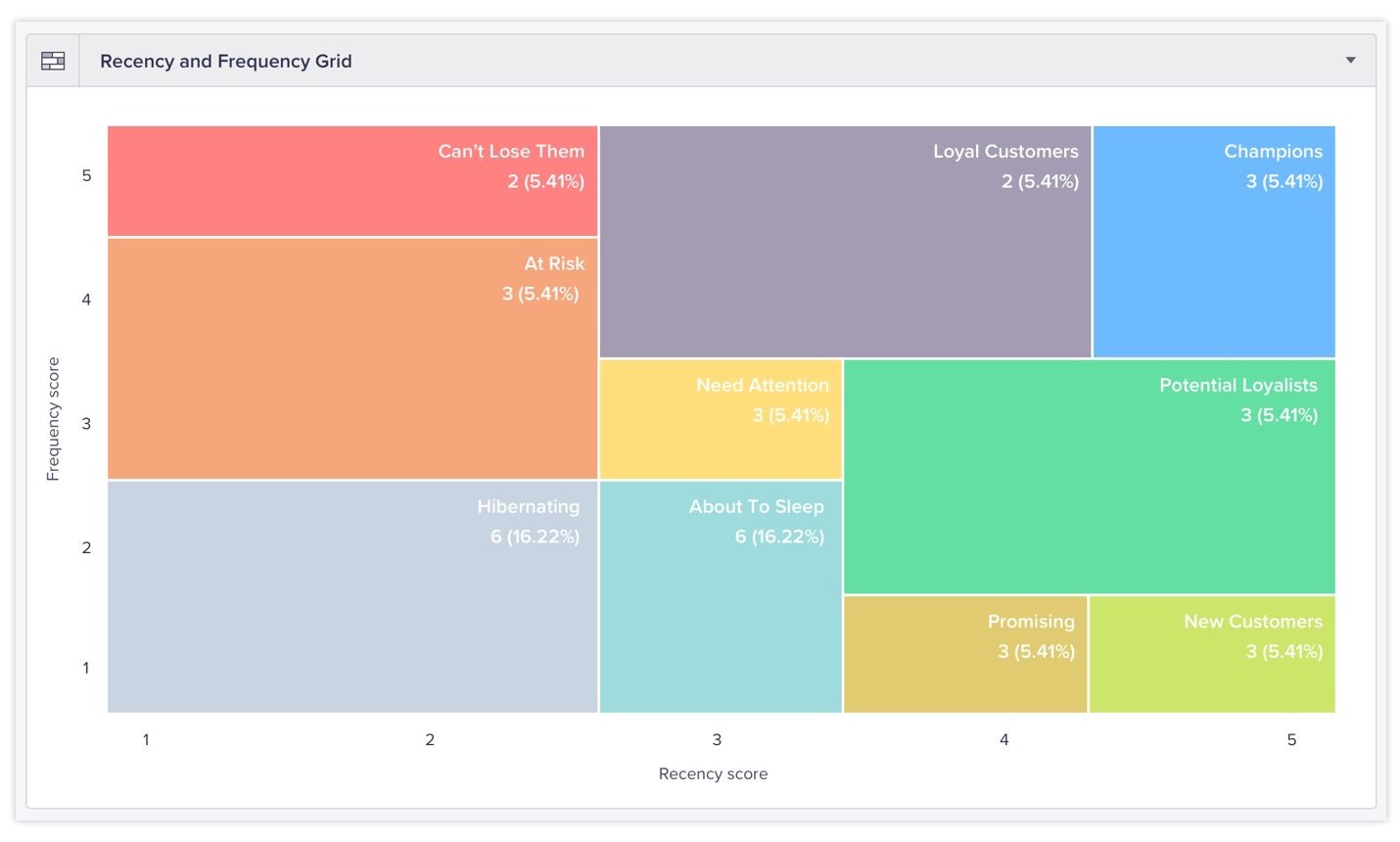
전체 고객군에 관한 분포의 왜곡 현상을 고려하여 ‘New User’군과 다른 군들을 나뉘어 RFM 모델을 독립적으로 적용하였습니다 . 독립적인 연산 과정 후 각 군들을 합친 후 통계량을 내는 부분에 있어서 스파크 파티션의 ‘Data Skewness’를 발견할 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
df.cache()
new_user_df = df.filter(df['max_sessionSeq'] == 1)
new_user_df = new_user_df.drop('max_sessionSeq', 'frequency', 'recency')
new_user_df = new_user_df.withColumn('segmentation', lit("00")) \
.select('cookieId', 'segmentation', 'monetary','session_frequency', 'recency_date')
print('New User Partition Size')
df_length = new_user_df.rdd.glom().map(len).collect()
print(df_length)
print('All partitino Size in ', len(df_length))
print('max Partition Size : ', pa.max(df_length))
print('min Partition Size : ', pa.min(df_length))
1
2
3
4
5
##
[35287, 34389, 35438, 34416, 34564, 34982, 35383, 35342, 34667, 34272, 35282, 34464, 34409, 34453, 35122, 35143, 35321, 35238, 34568, 34456, 34455, 34457, 34428, 34116, 35194, 12446]
All partitino Size in 26
max Partition Size : 35438
min Partition Size : 12446
1
2
3
4
5
6
print('Before First Cross Join')
df_length = df.rdd.glom().map(len).collect()
print(df_length)
print('All partitino Size in ', len(df_length))
print('max Partition Size : ', pa.max(df_length))
print('min Partition Size : ', pa.min(df_length))
1
2
3
All partitino Size in 1000
max Partition Size : 13
min Partition Size : 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
df = df.select(mean('frequency').alias('mean_frequency'),
stddev('frequency').alias('std_frequency'),
mean('monetary').alias('mean_monetary'),
stddev('monetary').alias('std_monetary'),
mean('recency').alias('mean_recency'),
stddev('recency').alias('std_recency')
) \
.crossJoin(df) \
.withColumn('scaled_frequency', (col('frequency') - col('mean_frequency')) / col('std_frequency')) \
.withColumn('scaled_monetary', (col('monetary') - col('mean_monetary')) / col('std_monetary')) \
.withColumn('scaled_recency', (col('recency') - col('mean_recency')) / col('std_recency'))
print('After first Cross Join & Preprocessing before second cross join')
df_length = df.rdd.glom().map(len).collect()
print('All partitino Size in ', len(df_length))
print('max Partition Size : ', pa.max(df_length))
print('min Partition Size : ', pa.min(df_length))
1
2
3
All partitino Size in 1000
max Partition Size : 13
min Partition Size : 0
1
2
3
4
5
6
7
8
9
new_user_df = new_user_df.select('cookieId', 'session_frequency', 'monetary', 'recency_date', 'segmentation')
result = df.union(new_user_df)
df.unpersist()
print('After Union cross join')
df_length = result.rdd.glom().map(len).collect()
print('All partitino Size in ', len(df_length))
print('max Partition Size : ', pa.max(df_length))
print('min Partition Size : ', pa.min(df_length))
1
2
3
All partitino Size in 2000
max Partition Size : 971
min Partition Size : 0
Join시 해당 파티션(Partition) 내에서 같은 키값을 갖는 데이터가 있어야 합니다. 만약 그렇지 않으면 주어진 키의 갯수와 파티션 내의 데이터를 맞추는 작업을 하는데 많은 비용이 발생합니다. CrossJoin을 함에 있어서 같은 데이터프레임을 활용하고 있으므로 앞에서 살펴본 crossJoin의 첫번째 경우와 같습니다.
다시 말해서 파티션의 크키의 변동이 없음을 확인할 수 있습니다. 하지만 새로운 고객군을 기존 데이터프레임과 합칠 때 개별적인 파티션의 크기 차이의 심화로 이후의 작업에서 연산 속도가 느림을 발견할 수 있었습니다. 그래서 드라이버의 maxResultSize를 1024가 아닌 더 높은 값으로 설정하여 Stage Failure를 막으면서 new_user_df와 df의 파티션 수를 최적화하고 Garbage Collection Tuning을 한 결과 어플리케이션의 실행 시간을 단축할 수 있었습니다.