
많은 기업은 효율적으로 마케팅을 집행하려고 노력합니다. 제가 속한 회사에서도 한정된 자원으로 효율적으로 고객을 터치하기 위해서 노력하고 있는데요. 일반적으로 새로운 고객을 확보하는 것보다 기존 고객이 다시 구매하도록 유도하는 것이 효율적입니다. 이미 회사는 천만에 가깝게 회원수들을 보유하고 있습니다. 기업이 고객께 가치를 제공할 수 있는 조합은 특정 고객에게 알맞은 상품을 찾는 것과 기업의 서비스에 알맞는 고객을 선정하는 것입니다. 제가 집중한 것은 확보된 고객을 대상으로 하는 CRM 마케팅입니다. 고객의 구매 확률 예측 모델이 배포되어 고객에게 실제로 적용되었고 거래액 및 AOV의 증대를 확인할 수 있었습니다. 구매 확률 예측 모델을 만들면서 고려했던 내용들을 공유드립니다.
Offsite 캠페인 최적화
커머스 플랫폼 기업마다 고객에 관한 정의를 다르게 내리지만 고객이 회사가 제공하는 서비스에 대한 가치를 느끼지 못할 경우 고객은 이탈합니다. 과연 회사는 고객이 원하는 것을 적절하게 제공하고 있을까요? 중요한 점은 비즈니스 목표는 최적화할 수 있는 수리적 지표로 표현돼야 합니다. 이 때 수집할 수 있는 데이터의 범위와 수집의 문제를 고려하는 것이 중요합니다. 최적화 지표가 분명할 때 ML 모델은 다양한 세분화 수준에서 설계될 수 있습니다.
E-commerce는 고객에게 온사이트 캠페인과 오프사이트 캠페인으로 나뉠 수 있습니다. 온사이트 캠페인은 고객이 앱이나 사이트에 입장했을 때 수 많은 정보들중 시의적절한 콘텐츠들을 제공합니다. 대표적으로 추천 시스템과 인앱 메시징이 있습니다. 오프사이트 캠페인은 고객이 앱에서 모종의 이유 혹은 구매 후 퇴장한 후에 고객이 놓칠 수 있는 회사의 새로운 정보를 제공하기 위해서 필요합니다.
Offsite 캠페인 과정
현재 진행되는 오프사이트 캠페인의 집행 과정은 다음과 같습니다.
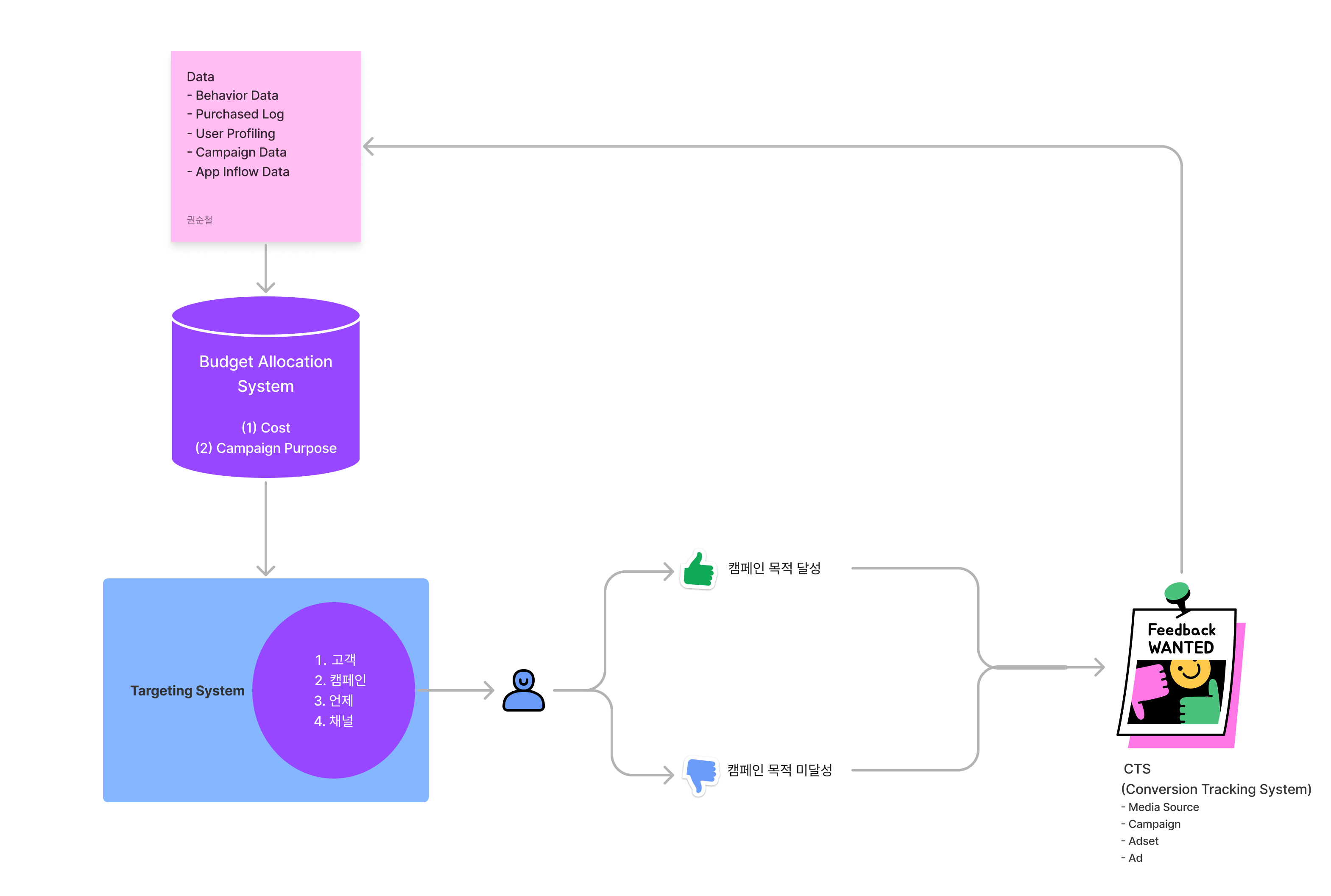
가장 먼저 오프사이트 캠페인 계획 단계에서 집행 예산, 기간, 프로모션의 종류 및 목적, 그리고 프로모션에 적합한 채널 선정과 같은 주요 항목들은 정해집니다. 이 때 예산 결정 후 Budget Allocation System을 ML 모델로 자동화하여 캠페인 목적에 맞는 예산 배분을 채널별로 진행할 수 있습니다. 위와 같은 하드 세그멘테이션이 결정된 후 캠페인 실행 단계에서 크게 세 가지를 고려해야 합니다.
- (1) 어느 고객께서 프로모션을 받는가?
- (2) 무엇이 적합한 프로모션의 특성인가?
- (3) 어느 시점에 프로모션을 보내야 하는가?
최적의 소재 찾기(2)는 일반적으로 사업부에서 선택지가 결정되고 제한적입니다(커머스 플랫폼 같은 경우 발송 소재는 쿠폰, 상품, 셀러입니다). 쿠폰 플레이는 패션 플랫폼에서 굉장히 중요하고 예산이 많이 집행되는 분야입니다. 그래서 저는 가장 먼저 최적화할 소재를 쿠폰으로 결정하였습니다. 중요한 점은 각 소재에 적합한 고객 세그멘테이션(1)입니다.
BUSINESS LOGIC
쿠폰 플레이와 연결되는 비즈니스 로직은 다음과 같습니다. 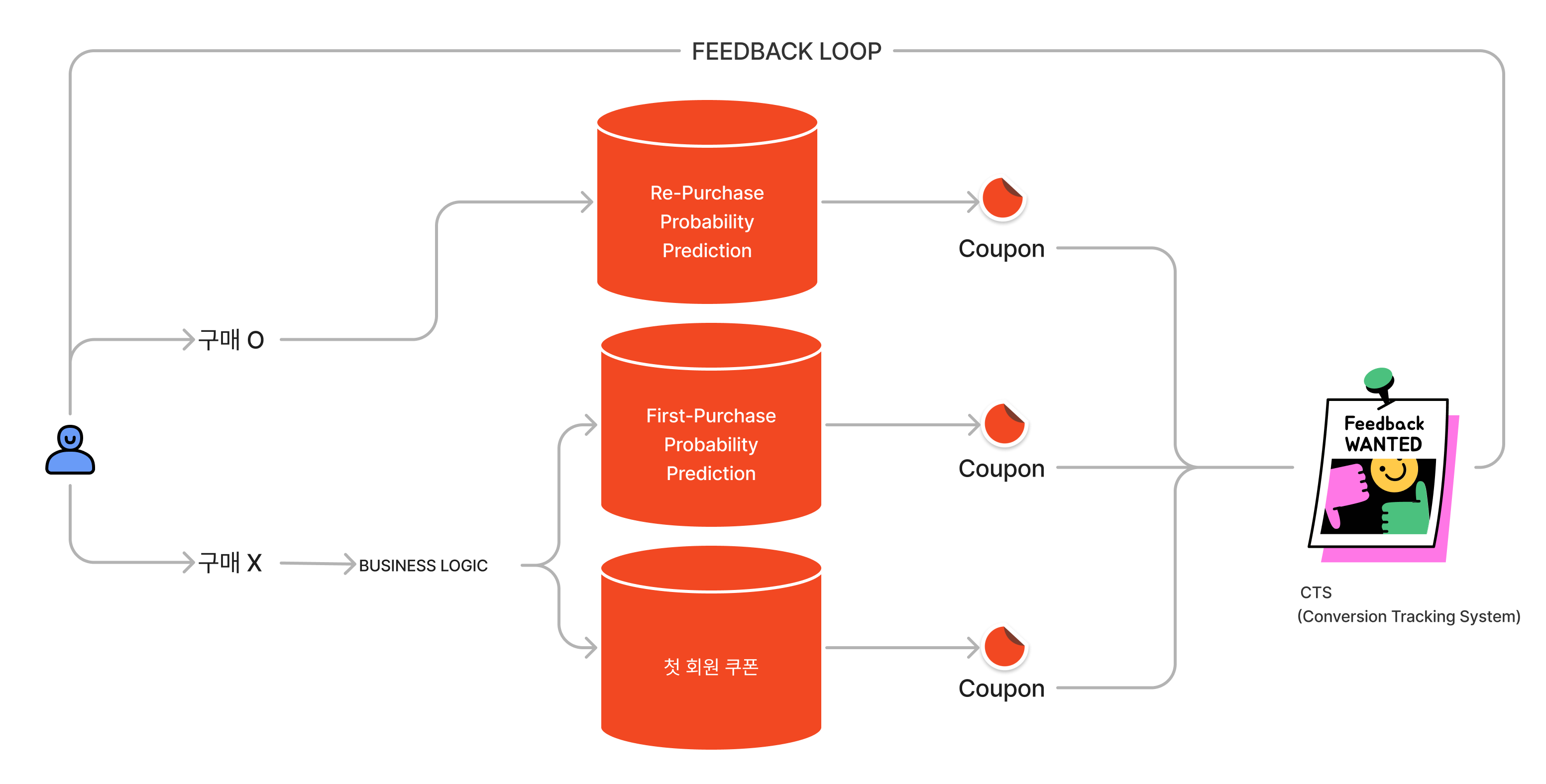
고객은 세 가지인 경우 쿠폰을 발급받습니다.
- (1) 회원 가입을 하고 첫구매를 하지 않았지만 사업부에서 정한 비즈니스 로직에 충족하는 고객
- (2) 회원 가입을 하고 첫구매를 하지 않으면서 사업부에서 정한 비즈니스 로직에 충족하지 않은 고객
- (3) 구매를 한 고객
쿠폰 플레이의 목적은 매출의 증대인데요. 이익은 일반적으로 다음과 같이 계산합니다.
\(Q(P - V) - C\)
- Q : 판매량
- P : 단위당 판매 가격
- V : 단위당 변동 캠페인 비용
- C : 고정 캠페인 비용
쿠폰 플레이 최적화는 앞에서 언급한 비즈니스 로직 이후 기존에 마케팅실에서 수동으로 진행하던 고객 세그멘테이션 작업 및 쿠폰비용 매칭을 데이터와 ML 모델을 통해 자동화하는 작업입니다. “첫 회원 쿠폰”같은 경우는 마케팅 조직에서 매월 쿠폰 발급량의 총액에 맞춰 일정 비율로 정하고 있습니다.
나머지 두개의 비즈니스 로직에 대응하는 고객 세그멘테이션 작업을 하기 위해서는 재구매 확률 예측 모델, 첫구매 확률 예측 모델이 필요합니다. 구매 확률 기반의 성향 모델링을 도입하여 비즈니스 문제를 푼 과정은 다음과 같습니다.
Feature Engineering
먼저 구매 확률 모델을 고객이 일정 기간내 구매를 할 것 같은 예측 태스크로 규정하였습니다. 그래서 고객의 구매 유무의 Time Window를 정하는 것이 중요한데요. Time Window를 정하기 위해 계절성을 아래와 같이 살펴보았습니다.
거래액에 관한 Seasonality Effect이 존재할까?
구매 확률 모델링을 하기 전에 먼저 거래액과 구매에 관한 계절성을 먼저 확인하였습니다. Seasonality는 Addictive Seasonality와 Multiplicative Seasonality로 나눌 수 있습니다. 예를 들어 다음과 같은 시계열 그래프가 있다고 가정하겠습니다.
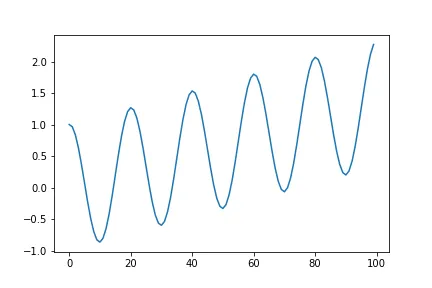
이 때 Addictive Seasonality일 경우 다음과 같이 표현할 수 있습니다.
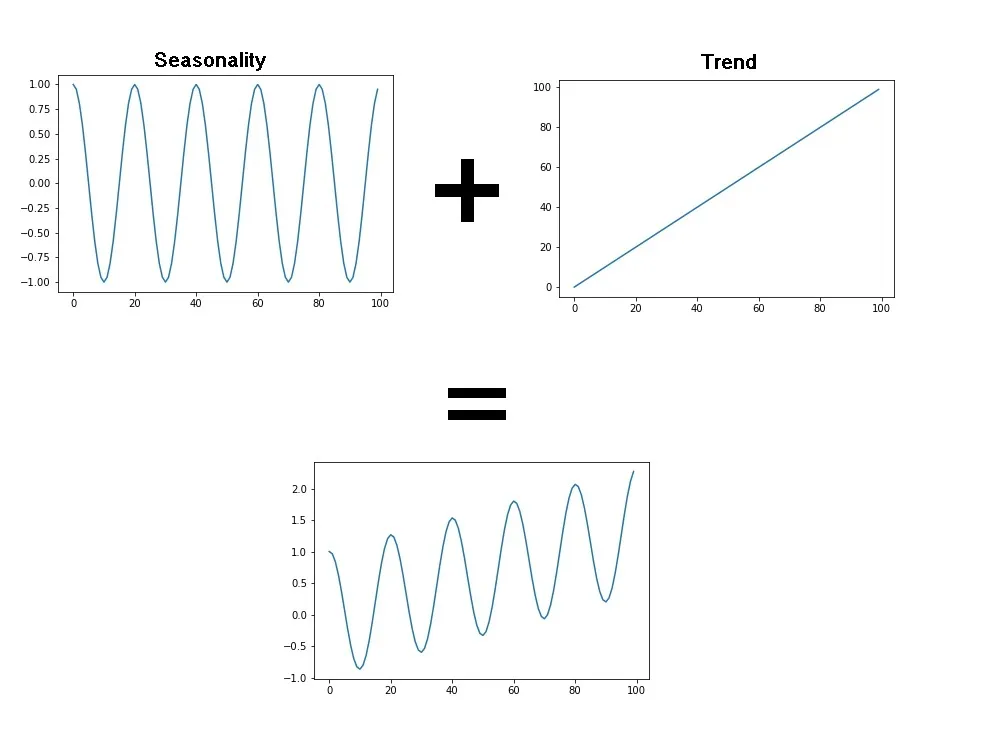
수식은 다음과 같습니다.
\(Y[t] = T[t] + S[t] + \boldsymbol{\varepsilon}[t]\)
- \(Y[t]\) : Time-series function
- \(T[t]\) : Trend(General tendency to move up or down)
- \(S[t]\) : Seasonality(Cyclick pattern occuring at regular intervals)
- \(\boldsymbol{\varepsilon}[t]\) : Residual(Random noise in the data that isn’t accounted for in the trend or seasonality)
다음으로 아래와 같은 시계열 그래프가 있다고 가정하겠습니다.
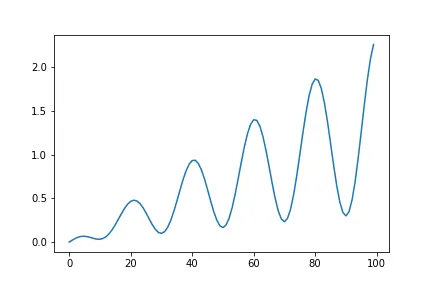
이 때 Multiplicative Seasonality일 경우 다음과 같이 표현할 수 있습니다.
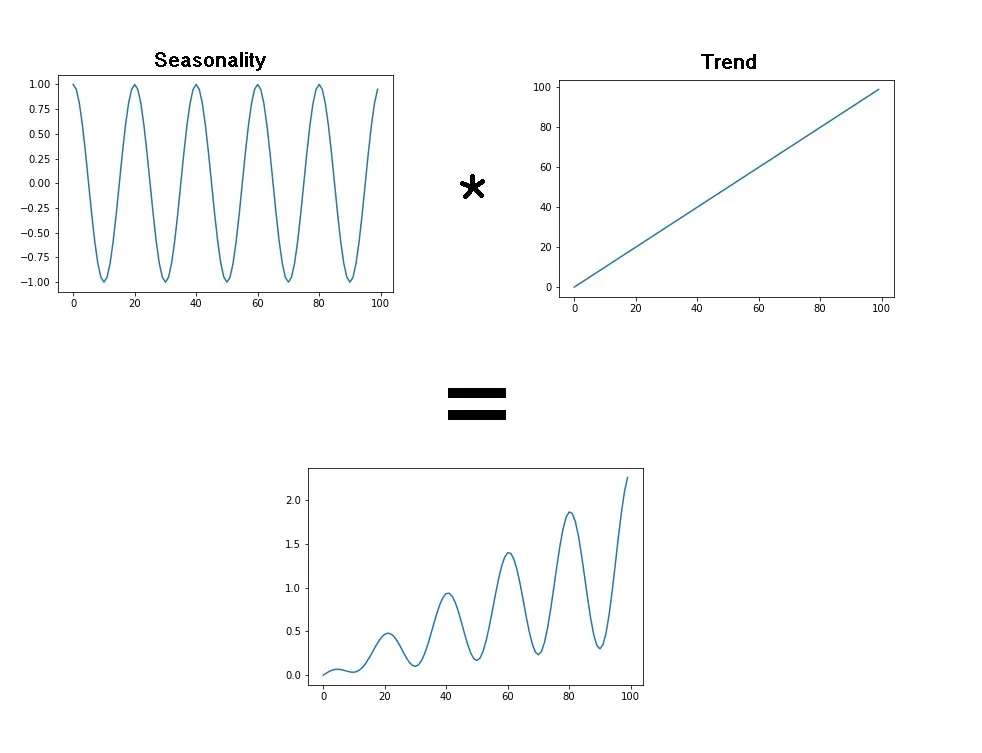
수식은 다음과 같습니다.
\(Y[t] = T[t] \times S[t] \times \boldsymbol{\varepsilon}[t]\)
- \(Y[t]\) : Time-series function
- \(T[t]\) : Trend(General tendency to move up or down)
- \(S[t]\) : Seasonality(Cyclick pattern occuring at regular intervals)
- \(\boldsymbol{\varepsilon}[t]\) : Residual(Random noise in the data that isn’t accounted for in the trend or seasonality)
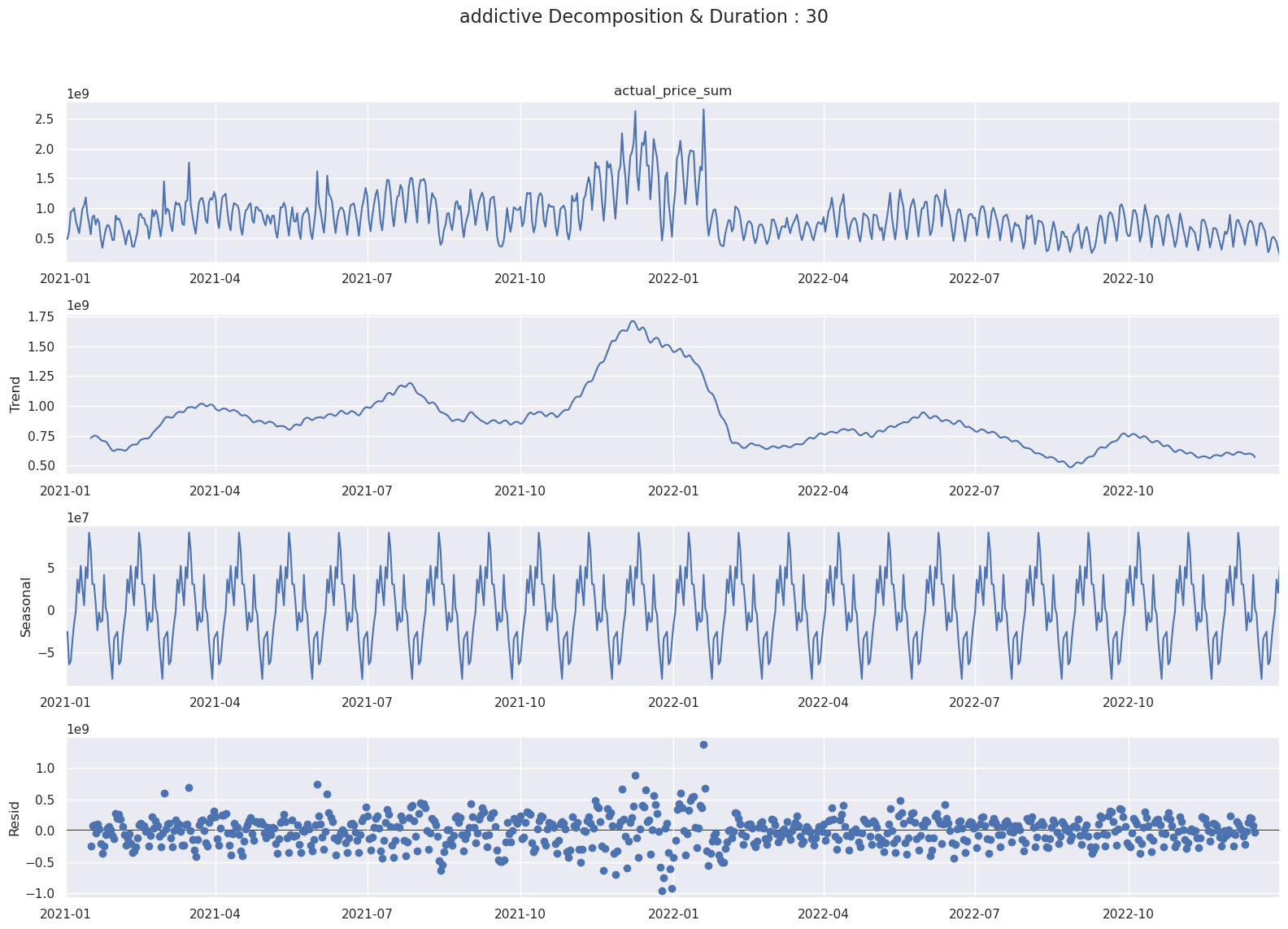
Period를 30일로 설정할 때 Multiplicative와 Addictive 방식으로 시계열 분해하면 다음과 같습니다.
- Multiplicative
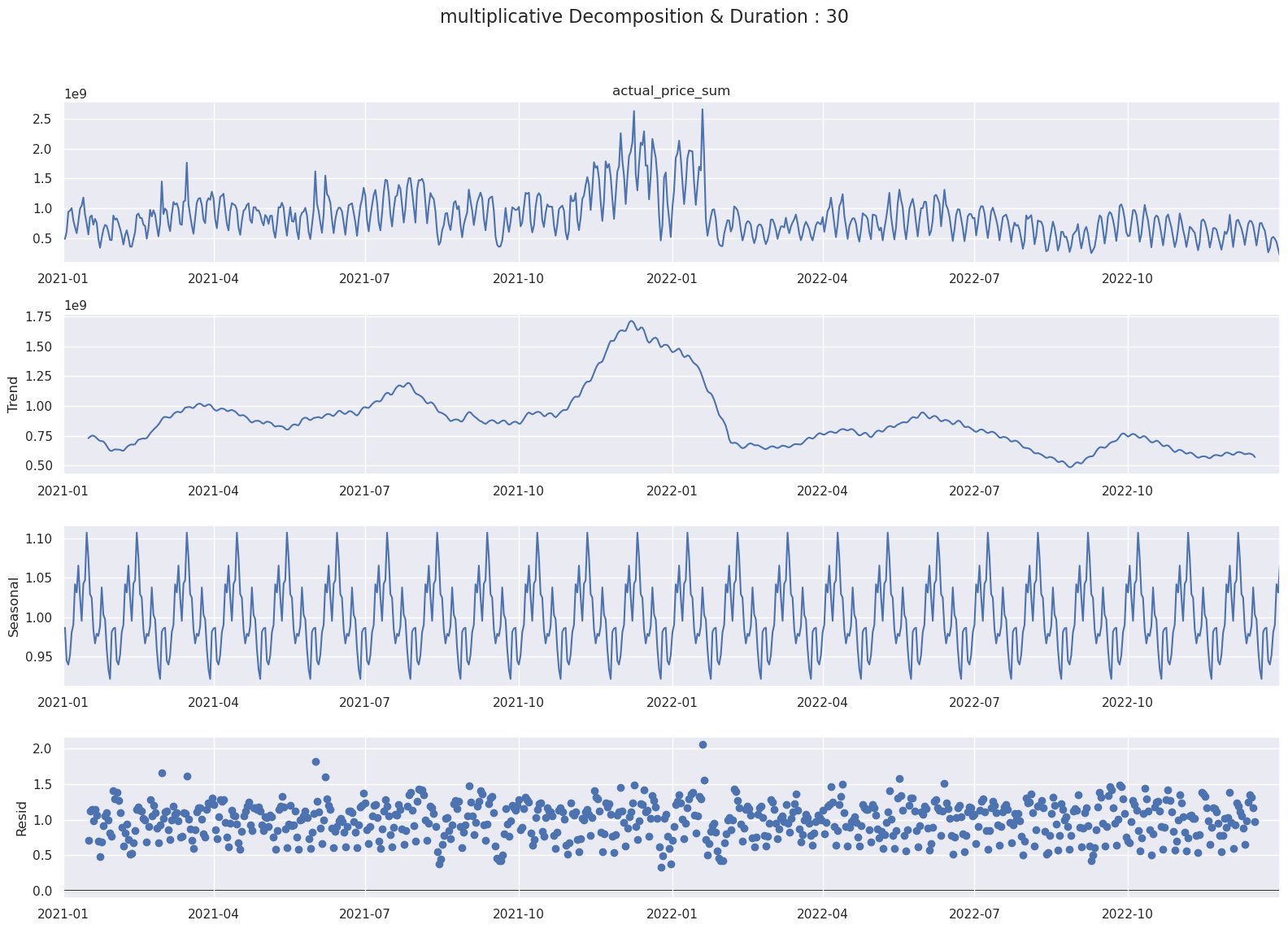
- Addictive
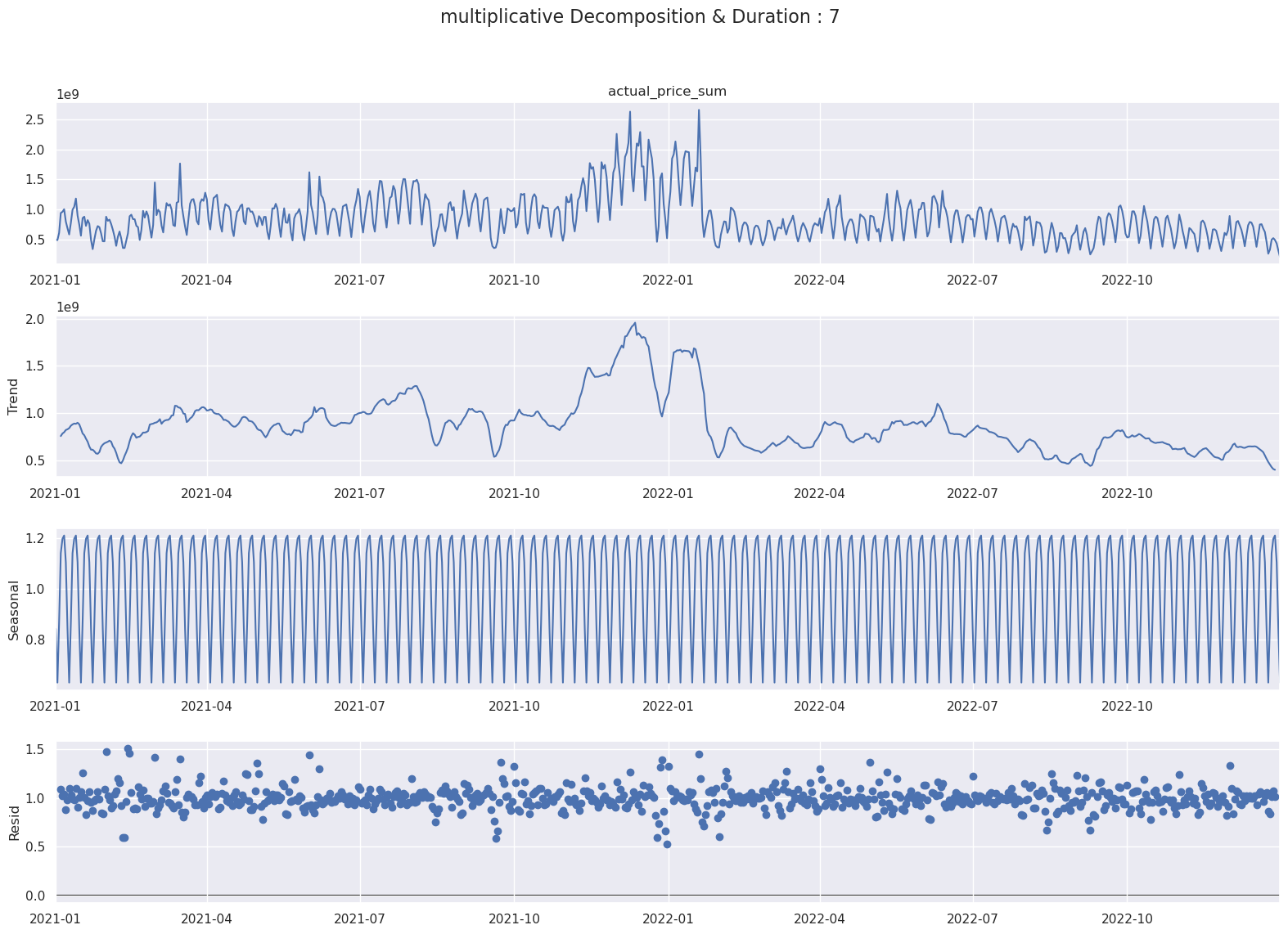
마찬가지로 Period를 7일로 설정할 때 Multiplicative와 Addictive 방식으로 시계열 분해하면 다음과 같습니다.
- Multiplicative
- Addictive
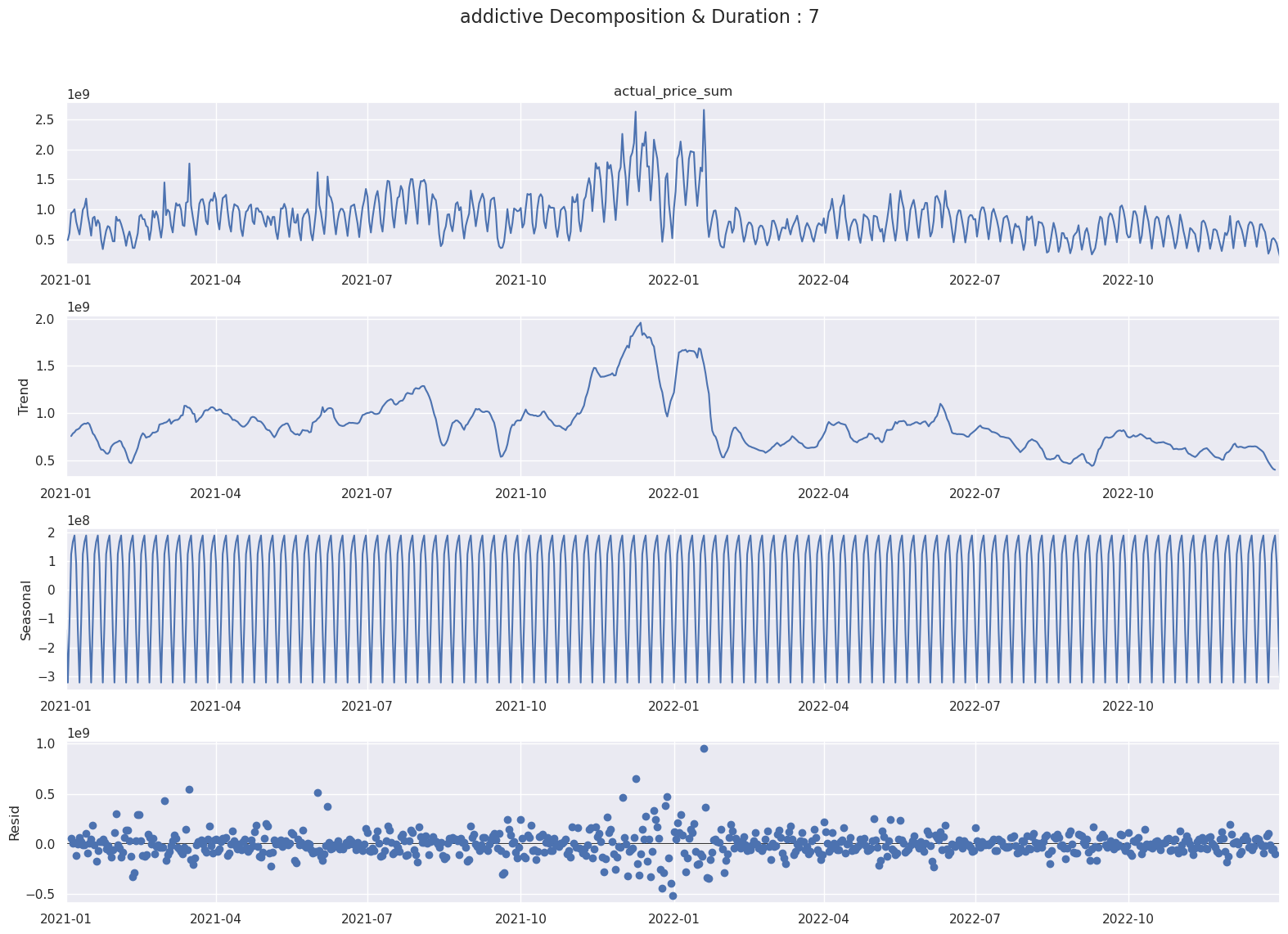
- 위의 그래프를 통해 수식은 일주일 그리고 한달에 관한 Addictive와 Multiplicative 방식으로 시계열 분해를 구성해도 무방한 것을 알 수 있습니다.
- 검증셋과 테스트셋의 Time Window를 한달의 시간으로 잡을 경우 모델이 한달 주기의 패턴과 동향을 파악할 수 있습니다.
- 다시 말해서 한달간의 주기성을 가진 데이터에 대해 모델을 검증하고 테스트하여서, 모델의 예측력과 일반화 능력을 올릴 수 있습니다.
Customer Lifetime Value Prediction Using Embeddings는 Random Forest를 사용해서 고객의 LTV와 이탈 확률을 예측하고 있는데요.
Data 클래스 기준으로 모델링 이후 Feature importance를 살펴보면 다음과 같습니다.
| Data Class | Overall Importance |
|---|---|
| Purchase history | 0.600 |
| Web/app session log | 0.345 |
| Customer demographics | 0.078 |
| Returns history | 0.017 |
Reference
- A Note on Deriving the Pareto/NBD Model and Related Expressions
- Predicting customer profitability during acquisition: Finding the optimal combination of data source and data mining technique
- Customer base analysis: partial defection of behaviourally loyal clients in a non-contractual FMCG retail setting
- Incorporating sequential information into traditional classification models by using an element/position-sensitive SAM
- Deep Embedding Forest: Forest-based Serving with Deep Embedding Features
- Profit Optimizing Churn Prediction for Long-Term Loyal Customers in Online Games
- Modeling partial customer churn: On the value of first product-category purchase sequences
- Investigating purchasing-sequence patterns for financial services using Markov, MTD and MTDg models
- Benefits of quantile regression for the analysis of customer lifetime value in a contractual setting: An application in financial services
- Customer Lifetime Value Prediction in Non-Contractual Freemium Settings: Chasing High-Value Users Using Deep Neural Networks and SMOTE
- Customer Lifetime Value Prediction Using Embeddings
- A DEEP PROBABILISTIC MODEL FOR CUSTOMER LIFETIME VALUE PREDICTION
- The Paper: “A Deep Probabilistic Model for Customer Lifetime Value Prediction
- An Overview of Multi-Task Learning in Deep Neural Networks
- Properties and benefits of calibrated classifiers
- A Comprehensive Guide on Model Calibration: What, When, and How
- Mining for the truly responsive customers and prospects using true-lift modeling: Comparison of new and existing methods
- Causal Inference and Uplift Modelling: A Review of the Literature