

지난 시간에는 팀원들과 Matrix Completion과 관련된 SVD1, ALS2, SGD의 개념을 살펴보았습니다. 이번 시간에는 이커머스에서 추천 모델의 최종 단계인 유사도(Similarity)를 계산하는 부분과 지표(Metric)를 점검해보았습니다.
Similarity
상품 또는 고객을 벡터로 표현한 뒤 벡터 간의 유사도를 비교할 때 일반적으로 ‘Non-geometric measure’와 ‘Geometric measure’로 나눌 수 있습니다.
Non-geometric measure
Non-geometric measure와 관련하여 많은 유사도 지표가 있지만 대표적으로 몇 가지 지표를 소개하면 다음과 같습니다.
Pearson Correlation Coefficient
- X가 증가할 때 Y가 증가할 수록 양의 값을 가집니다.
- 범위는 -1 ~ 1입니다.
Jaccard Coefficient
- 두 개의 집합 X,Y가 있을 때, Jaccard Index는 X,Y의 교집합의 원소 갯수를 합집합의 원소 갯수로 나눈 값입니다.
- 자연스럽게 Jaccard Index는 0~1 사이의 값을 가집니다.
- 유사성을 측정하는 Jaccard Index와는 다르게 Jaccard distance는 비유사성에 관한 측도입니다.
- Jaccard Index와 Jaccard distance는 서로 반비례 관계입니다.
- X,Y가 공통으로 가지는 상품 또는 고객은 중요하지만, X,Y 모두 존재하지 않는 상품, 고객은 배제합니다.
Euclidean Similarity vs Cosine Similarity
가장 대표적인 유사도 함수들 중 코사인 유사도와 유클리드 유사도가 있습니다. 먼저 각 유사도의 정의를 살펴보겠습니다.
유클리드와 코사인 유사도의 정의는 다음과 같습니다.
이 두 유사도간의 비교를 예시와 함께 설명한 포스트3가 있습니다. 보다 자세한 내용을 원하시는 분은 참고해 주세요. 결론적으로 다음을 알 수 있었습니다.
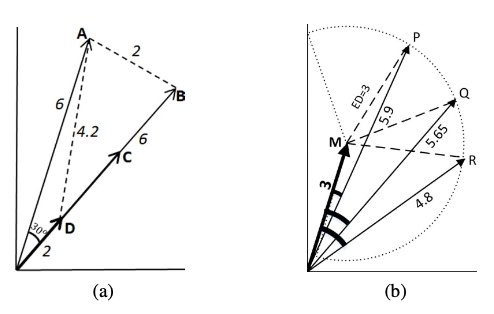 Euclidean and Cosine example
Euclidean and Cosine example
- 수식의 의미를 생각해 보았을 때 유클리드 거리 측도는 두 상품간의 각도는 고려하지 않고 두 상품 벡터가 위치한 좌표상의 거리만을 고려합니다.
- 그러므로 최소 거리인 0부터 무한대까지의 범위를 가집니다.
- 코사인 유사도를 측도로 사용할 경우 최솟값은 -1이고 최대값은 1입니다.
- 벡터의 크기를 고려하지 않고 상품의 비율을 고려하여 측정합니다.
- 위의 이미지중 첫번째 그래프에서 알 수 있듯이 코사인 유사도를 기준으로 상품 D와 다른 상품들간의 가까운 순위를 정하면 다음과 같습니다.
- 상품 C = 상품 B > 상품 A
- 하지만 실제로는 D를 기준으로 보았을 때 상품 C와 상품 B는 분명한 차이가 존재합니다.
- 또한 상품 A와 상품 B중 유클리드 거리 측도로 보았을 때는 상품 A가 조금 더 유사한 상품입니다.
- 이렇게 어떤 유사도를 최종 단계에서 선택하느냐에 따라서 추천되는 상품이 달라질 수 있으므로 상품 유사도 간의 비교를 반드시 고려해야 합니다.
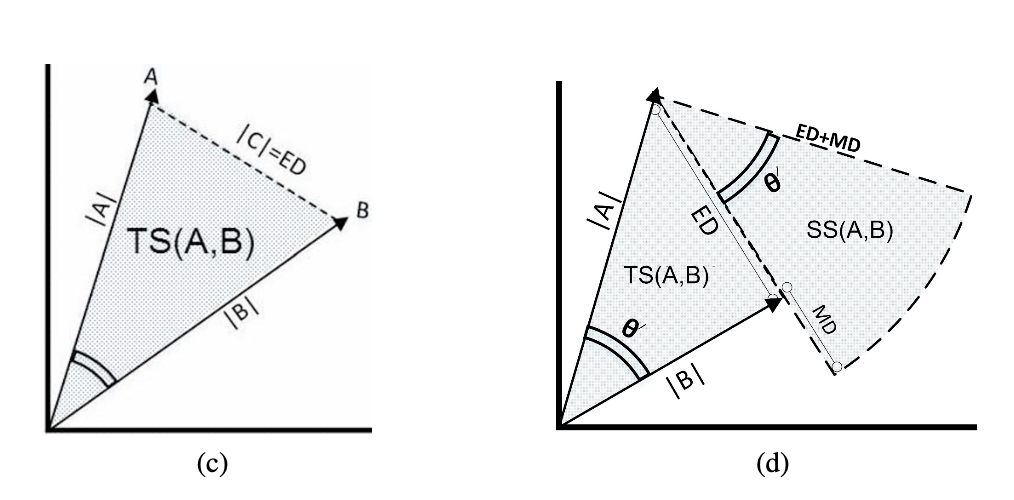 TS and SS
TS and SS
- 유클리드 거리 속성과 코사인 유사도의 특징을 혼합한 지표는 만들 수 없을까요?
- 두 벡터를 기점으로 만들어지는 삼각형의 넓이를 유사도로 설정하면 어떨까요?
- SAS(Side Angle Side)[삼각형의 한 각이 다른 삼각형의 각과 합동이면서 각을 이루는 두 변의 비율이 서로 비례하면 삼각형은 유사하다]를 활용하겠습니다.
- 위의 그림처럼 N차원의 벡터(A,B)의 강도를 표현하면 다음과 같습니다.
\[|A| = \sqrt{\sum^N_{k=1}(A_n)^2} \, and \, |B| = \sqrt{\sum^N_{k=1}(B_n)^2}\]- 코사인 유사도를 활용하여 양변 사이의 각(\(\theta)\)을 구할 수 있습니다.
- 하지만 위의 (a) 그래프에서 B,C 사이의 각이 형성되지 않습니다. 이 점을 고려하여 각(\(\hat{\theta)}\)은 다음과 같이 계산합니다.
- 절대적인 숫자는 정해지지 않았지만 계산의 편리함을 위해서 10 미만은 사용하지 않습니다.
\[\hat{\theta} = cos^{-1}(V) + 10\]- TS(Triangle’s Area Similarity)는 위의 정보들을 활용하여 다음과 같이 구할 수 있고 다음의 사실을 알 수 있습니다.
- 두 벡터(A,B)가 서로 유사할 수록 두 벡터를 이루는 삼각형의 넓이는 줄어듭니다.
- 두 벡터가 완전히 일치하면 삼각형의 넓이는 0입니다.
\[TS(A,B) = \frac{|A|\, \times |B|\, \times \, sin(\hat{\theta})}{2}\]
하지만 TS도 단점이 존재하는데요.

Metric
이커머스 도메인에서 추천 시스템의 목적은 무엇일까요? 비즈니스 관점에서 보았을 때 “신규 고객 확보”가 중요한 이커머스 사이트인 경우, CTR과 구매 전환률을 추천 시스템을 통해 올리는 것이 중요할 수 있습니다. 하지만 “고객 충성 유형”에 속하는 이커머스 사이트인 경우 추천 시스템을 통해 단기적인 CTR과 Conversion의 증가를 달성하였지만 장기적인 측면에서 보았을 때 고객 경험이 현저히 떨어지므로 가장 최악의 상황인 완전 이탈을 경험할 수도 있을 것입니다. 이렇게 정답이 없어 보이는 추천 문제에 맥락을 부여하여 해답을 찾으려는 여러 연구자들이 존경스럽네요. 도메인과 자신의 조직이 처한 상황에 따라 추천의 목적이 다르고 목적에 따라서 추천을 평가하는 지표를 선택하는 과정은 목적을 함축하므로 굉장히 중요합니다. 서로 다른 관점에 따른 추천 엔진에 관한 지표를 소개하겠습니다.
Online Metric
- 일반적으로 비즈니스 환경에서 수익 최대화를 위해서 추천 시스템을 도입할 때 얼마만큼 추천 시스템이 고객의 행동에 영향을 주는지 측정하고 싶습니다. 이런 예측은 고객의 문맥이나 의도 그리고 이커머스 도메인의 성격에 따른 다양한 요인들의 결합들에 영향을 받습니다. 이것을 파악하는데 있어 사실 Online Test는 Offline Test에 비해 훨씬 효과적입니다.
- 이커머스상에서 추천 시스템을 운영할 때 비즈니스 관점에서는 다음을 생각할 수 있습니다.
- 고객이 얼마나 많은 카테고리에 해당하는 상품들을 추천받고 있는가?
- CTR(Click-through rate)가 추천 엔진을 통해 얼마만큼 증가했는가?
- 구매 전환율(Conversion)이 추천 엔진을 통해 얼마만큼 증가했는가?
- 이커머스 사이트의 매출액이 추천 엔진을 통해 얼마만큼 증가했는가?
- 고객 이탈이 추천 엔진을 통해 얼마만큼 감소했는가?
- 위와 같이 추천 시스템의 효과를 측정하는 방법과 요소들은 문맥에 따라 상당히 다양합니다.
- 하지만 온라인 테스트를 진행할 때는 일반적으로 전체 고객들 중에서 샘플링한 뒤 추천 엔진의 평가 요소를 단일화해야 합니다.
- 만약 유저의 인터페이스를 평가하고 싶다면 추천 시스템에 사용되는 모델들은 고정해야 합니다.
- 반면 추천 시스템의 모델들을 평가하고 싶다면 추천 시스템를 구성하는 다른 요소들은 고정해야 합니다.
- 하지만 온라인 테스팅 시스템을 구축하는 데 상당한 시간이 소요됩니다.
- 또한 고객의 반응을 직접적으로 알 수 있는 지점에서 ‘고객의 불만족’을 맞이할 수 있습니다.
- B2C 업체인 경우 고객의 이탈을 추천 엔진 고도화를 위해 감수할 수도 있습니다.
- 이 점에서 특정 B2B 솔루션 업체인 경우 B2C 업체와는 다르게 검증된 추천 엔진을 제공해야 합니다.
- 그리고 아직 추천 엔진이 도입 전인 경우 Online Test는 힘들 수 있습니다.
Offline Metric
Online Test의 값비싼 비용을 상쇄하기 위해 Offline Test를 현업에서 많이 사용하고 있습니다. Offline Metric을 통한 추천 모델의 평가는 학습 데이터와 테스트 데이터를 분리한 후 학습 데이터를 통해 추천 모델을 학습 시킨 뒤 모델러가 정의한 오차 함수와 테스트 데이터를 통해 모델의 성능 평가하는 방식입니다.
Accuracy and Error based methods
정확도를 기반으로 추천의 성능을 평가하는 지표들 중 몇 가지(MAE(Mean Absolute Error), MSE(Mean Squared Error), RMSE(Root Mean Squared Error)를 살펴보겠습니다. 먼저 각 수식을 전개하면 다음과 같습니다.
RMSE와 MAE는 서로 어떤 장단점을 가질까요?
- MAE는 오차(실제 값과 추천 시스템가 출력한 예측 값간의 차이)에 대한 평균을 의미합니다.
- RMSE는 오차를 제곱한 값의 평균에 루트를 덧붙였습니다.
- 수식상 RMSE는 MAE에 비해 절대 작을 수 없습니다4.
- 만약 오차값이 극단적으로 클 경우에는 극단치에 편향을 주지 않는 MAE를 선택하여 추천 시스템의 성능을 평가해야 합니다.
- 오차함수에서 절대값을 사용하지 않고 제곱근을 사용하는 RMSE는 MAE에 비해 Gradient나 거리를 계산할 때 수학적으로 훨씬 편리합니다.
Decision support methods
‘Desicion support methods’는 고객이 좋은 상품을 선택하고 기호품이 아닌 상품을 배제하도록 도울 수 있는 지표입니다. 대표적으로 정밀도(precision)와 재현율(recall)이 있습니다.
| Positive Prediction | Negative Prediction | |
|---|---|---|
| Positive Class | TP(True Positive) | FN(False Negative) |
| Negative Class | FP(False Positive) | TN(True Negative) |
- CTR을 예시로 정밀도와 재현율의 의미를 살펴보겠습니다.
- 정밀도는 클릭할 것으로 예측되는 상품들 중에서 실제로 클릭한 경우를 의미합니다.
- 재현율은 클릭한 상품들 대비 예측 모델이 정확히 클릭할 것으로 예측한 비율을 말합니다.
- 추천 모델의 Output은 일반적으로 고객이 클릭할 가능성이 높은 Top N개의 상품을 리스트 형태로 묶은 형태입니다.
- 분모에 주목해 주세요. “클릭할 것으로 예측 되는 상품수” 에 비해 “고객이 실제로 클릭한 상품수”는 특수한 도메인의 이커머스 사이트를 제외하고 현저히 작을 것입니다.
- 유저가 한 세션에서 두 개의 상품을 클릭한 경우 Recall 값의 경우는 세 가지 밖에 없을 것입니다.
- 0/2[두 개의 상품들 중 하나도 예측 모델이 예측 못한 경우]
- 1/2[두 개의 상품들 중 예측 모델이 하나를 올바로 예측한 경우]
- 2/2[두 개의 상품들 중 예측 모델이 두 개를 올바로 예측한 경우]
- 이런 특성 때문에 추천에서는 재현율 보다는 정밀도를 일반적으로 사용하는 것 같습니다.
Ranking Based Methods
‘Accuracy and Error based methods’와 ‘Decision support methods’는 전반적인 추천 시스템의 성능을 평가할 수 있는 지표입니다. 하지만 CTR의 예시에서 알 수 있듯이 추천의 최종 형태는 일반적으로 여러 상품들이 담긴 리스트 형태로 나옵니다. 추천 리스트 안의 순서를 반영하여 평가할 수 있는 지표를 생각해볼 수 있습니다.
MRR(Mean reciprocal Rank)
- MRR은 “가장 관련성이 높은 상품이 추천 상품 셋의 몇 번째에 위치했나”(Binary relevance based metrics)를 알아보는 지표입니다.
- 먼저 MRR을 구할 때 필요한 준비물은 다음과 같습니다.
1
2
3
4
for each user u:
(1) 추천 상품 리스트 생성합니다.
(2) 가장 관련 있는 상품의 순서를 구합니다.
(3) 두번째 과정에서 구한 순서를 역을 취합니다.
- 구체적인 MRR의 정의는 다음과 같습니다.
직관적인 예시를 통해 살펴보겠습니다.
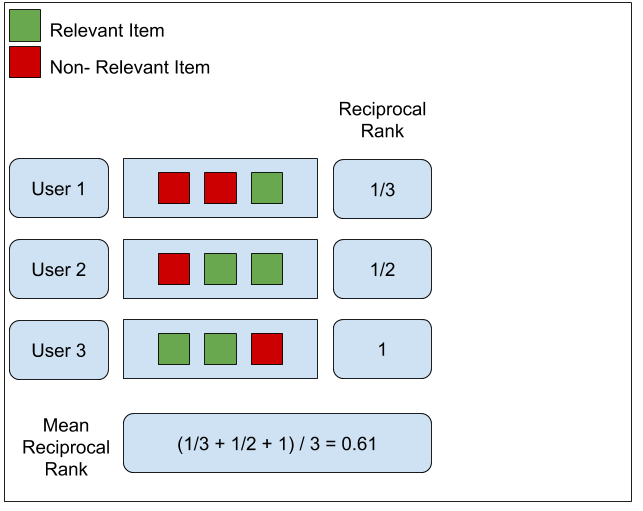 MRR metric example
MRR metric example
- 이렇게 가장 연관성이 높은 상품에 집중하는 점은 필연적으로 장단점을 만듭니다.
- 계산하고 해석하기 좋은 지표입니다.
- 가장 관련 있는 상품에 집중하는 것은 “나를 위한 최고의 상품”이 목적일 때 가장 최적일 것입니다.
- 반면 상품 추천 리스트의 다양한 상품들을 평가 대상으로 삼을 경우에는 적절하지 않습니다.
MAP(Mean Average Precision)
- ‘Decision support methods’에서 살펴본 P(Precision)@N은 ‘n개의 추천 상품들 중에서 어느 정도 비율로 상품이 선택되었는지’를 파악할 수 있지만 추천 상품의 순서를 반영하지 않습니다.
- AP는 다음과 같은 방법으로 계산을 하는데요.
1
2
3
4
5
for each user u:
추천 상품 리스트 생성합니다
for each relevant item:
리스트의 정밀도를 계산합니다.
정밀도의 sub-list에 대하여 평균을 계산합니다.
- 최종적으로 user-level의 precision에 대해 평균을 구하면 MAP값이 산출됩니다.
- 사실 진정한 AP의 매력은 PR-curve의 면적을 구하는 것입니다.
- 하지만 plot 형태의 지표는 해석하고 계산하기 불편합니다.
- 그래서 정확하지 않지만 축약할 수 있는 평균으로 연구자들이 지표를 대체한 것 같네요.
- 다른 지표와 마찬가지로 예시를 통해 쉽게 파악해 보겠습니다.
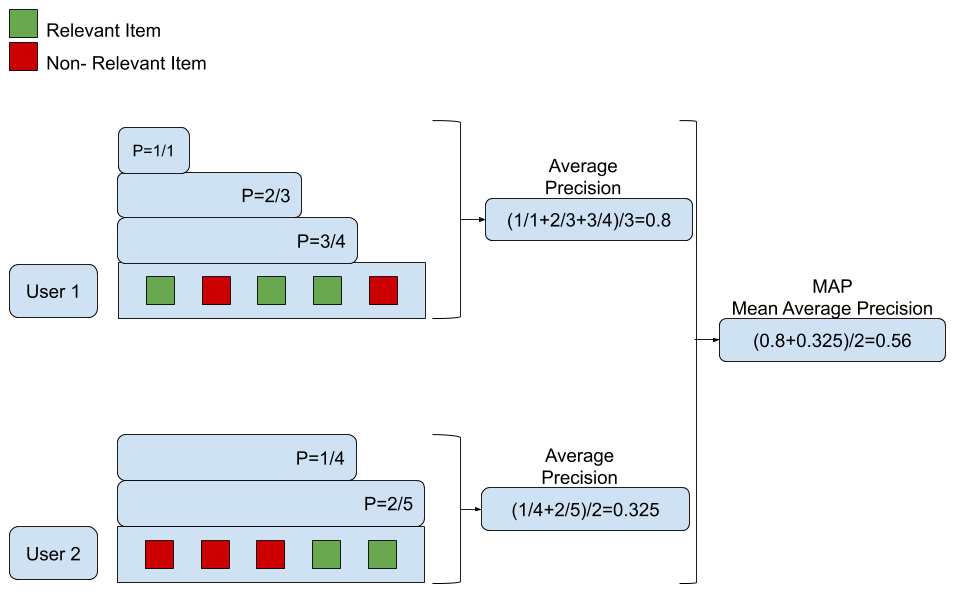 MAP metric example
MAP metric example
- MRR이 가장 관련성 있는 첫번째 상품에 초점을 맞춘것과는 다르게 MAP는 전체 추천 상품 리스트를 다룹니다.
- 추천리스트 중에서 높은 순위에 배치된 상품들에는 더 높은 오류 가중치를 부여합니다.
- MRR과 마찬가지로 “Binary relevance based metrics”에 속하므로 관련이 있는 상품과 관련성이 없는 상품으로 미리 데이터를 전처리 해야 합니다.
- 다양한 수치형값들이 존재할 때 이 값들을 임의적으로 데이터를 이진화하는 과정에서 정보의 편향이 발생하네요.
nDCG
- nDCG는 세 부분으로 구성됩니다.
- CG(Cumulative Gains) : 관련성(Relevancy)을 기준으로 상품들을 수치화한 후 더합니다.
- 정의에서 알 수 있듯이 가장 관련 있는 상품이 상대적으로 관련성이 작은 상품에 비해 높은 점수를 받습니다.
- 하지만 밑의 수식에서 알 수 있듯이 아직까지 ‘CG’ 자체는 추천 리스트의 순서를 반영한 지표가 아닙니다.
\[CG(Cumulative \ Gains) = \sum^p_{i=1} \ rel_i\] - 상품의 관련성을 정량화한 것은 살리면서 동시에 상품 추천 리스트에서 낮은 순위로 등장하는 상품들에 페널티를 주는 방법을 생각해 볼 수 있는데요.
- 구체적으로 상품의 관련성 지표값을 추천 리스트에 등장한 순서로 나눌 수 있을 것입니다.
DCG(Discounted Cumulative Gain)의 수식을 한번 보겠습니다.
\[DCG(Discounted \ Cumulative \ Gains) = \sum^p_{i=1} \ \frac{2^{rel_i}-1}{log_2{(i+1)}}\]- 하지만 추천 리스트의 길이 자체가 다를 경우는 어떻게 대응해야 할까요?
- 예를 들어 30개의 상품 추천 셋에서 가장 관련도가 높은 상품이 5번째 배치될 때와 15개의 상품 추천 셋에서 관련도가 가장 높은 상품이 5번째 놓였을 때의 ‘DCG’는 어떨까요?
- n(추천 상품의 리스트 수)를 정규화할 필요가 있어 보입니다.
\[IDCG_p = \sum^{|REL_p|}_{i=1} \ \frac{2^{rel_i}-1}{log_2{(i+1)}}\]
\[nDCG_p = \frac{DCG_p}{IDCG_p}\]
- CG(Cumulative Gains) : 관련성(Relevancy)을 기준으로 상품들을 수치화한 후 더합니다.
- 예시를 통해 확인해 볼까요?
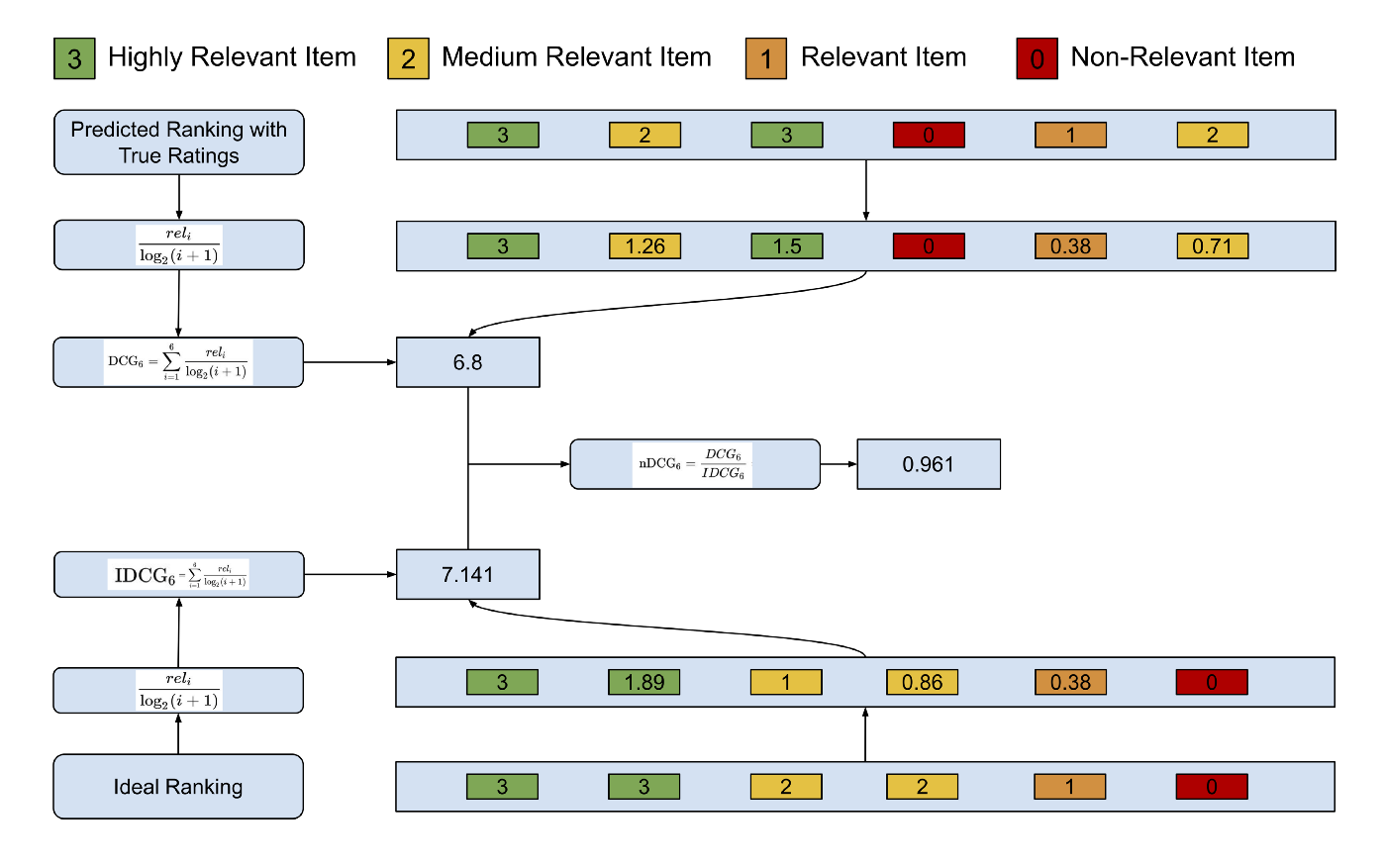 ndcg_metric_example
ndcg_metric_example
글을 마치면서..
지금까지 이커머스 추천 모델에서 마지막 부분에 속하는 유사도와 지표를 살펴보았습니다. 지면에 기술하지 않았지만 이커머스에서 추천 시스템을 도입할 때 수 많은 요소들(i.e.비즈니스에서 가장 중요한 KPI 결정하기, 고객의 행동 심리학적 요소들)을 고려해야 합니다. 그리고 무엇보다 최근 고객의 이커머스상의 행동 패턴은 오프라인에서의 행동 패턴과는 다르게 비선형적이고 굉장히 복잡해 지고 있습니다. 그래서 ‘온사이트와 오프사이트 상에서 고객의 행동 패턴을 정교하게 정량화하고 연결하여 모델에 어떻게 반영하느냐’가 앞으로 중요한 문제가 될 것 같습니다. 이런 점들이 추천 태스크를 정말 어렵게 하지만 사람의 반응을 즉각 확인할 수 있다는 점에서 매우 흥미롭기도 합니다.
Reference
- Arguments against avoiding RMSE in the literature
- Side-Angle-Side Proof
- A Hybrid Geometric Approach for Measuring Similarity Level Among Documents and Document Clustering
- Evaluating Recommender Systems: Root Means Squared Error or Mean Absolute Error?
- What does RMSE really mean?
- MRR vs MAP vs NDCG: Rank-Aware Evaluation Metrics And When To Use Them
- Mean Average Precision (MAP) For Recommender Systems
- Contrasting Offline and Online Results when Evaluating Recommendation Algorithms
- A Survey of Accuracy Evaluation Metrics of Recommendation Tasks